
Using Bright Data's "Scraping Browser" to by-pass CAPTCHA's and other protection when monitoring pages
For many websites - simply using a proxy is not enough, the website is using much more complex anti-robot software to detect the actual browser that is being used, not just the IP connection or headers (including common headers such as user-agent and others)
You need a better way to simulate a real browser - A scraping browser is different to a proxy, a proxy just tunnels your connection but the Browser still looks the same, with a scraping browsers you are also simulating a real browser hidden away in Bright Data's infrastructure.
As it turns out, many websites are probing much deeper into your browser - analysing the response from your 2D and 3D/GPU videocard is just one of the tactics they use.
Unfortunately for many headless Chrome sessions it means they stand out all too easy - their "fingerprint" is just too obvious, they dont have anything that resembles a real video card or other hardware attached.
The result is - you get pushed to enter a CAPTCHA or other similar anti-robot mechanism.
But there is a solution, whilst not guaranteed - it definitely helps a lot!
The clever people over at Bright Data have added a "Scraping Browser" to their offers, which more precisely simulates a real browser than just about anything you can try to run yourself.
(note: this functionality in changedetection.io will be released late November 2023, but you can try it now under the current master tag from our GitHub or dev tag from our Docker Hub)
More information about Bright Data's scraping browser can be found here.
Here's how to setup Bright Data's "Scraping Browser" with changedetection.io
Head on over to your Bright Data control panel - When you sign up using this link - https://brightdata.grsm.io/n0r16zf7eivq - BrightData will match any first deposit up to $150.
Once logged in - click on "Scraping Browser"
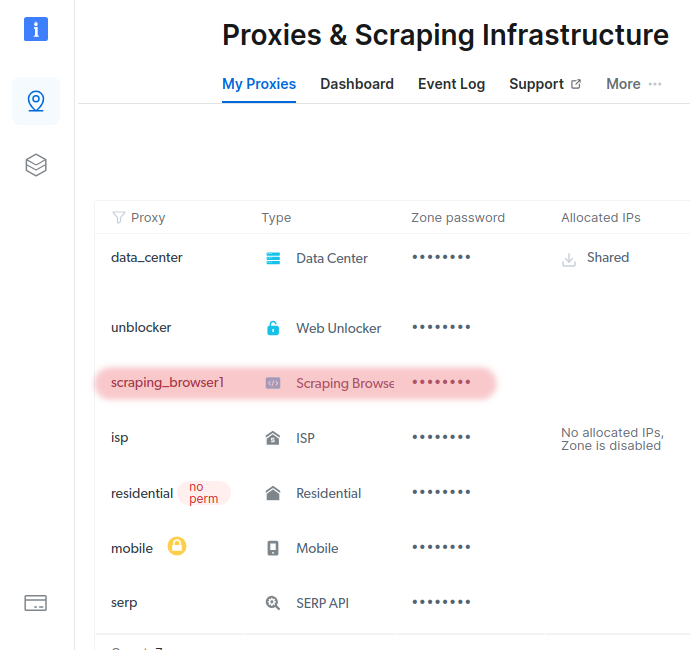
Now we will copy the special "Connection address" so changedetection.io knows how to find the Scraping Browser, click on Check out code and integration examples on the bottom right.
It's also worth considering here that you can add on extra residential proxies , residential proxies also greatly increase your chance of skipping past any potential CAPTCHA issues, but for now we will continue with the default setup.
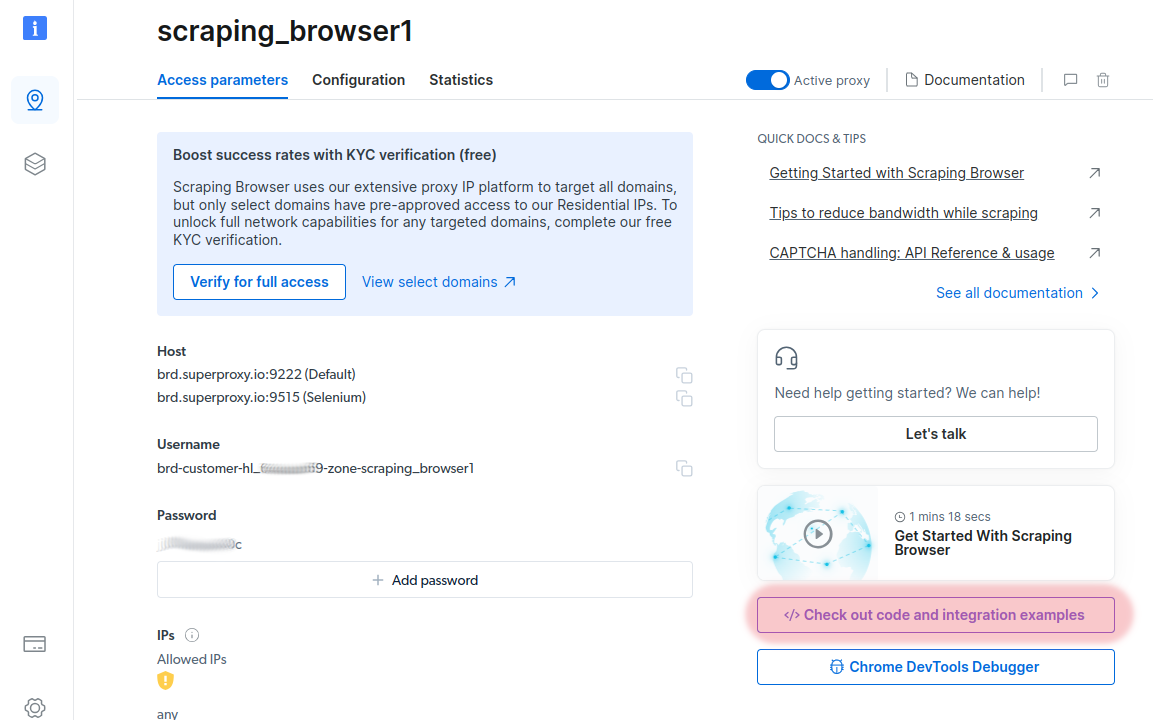
Copy the text from the next page into your clipboard, it will start with wss://, be sure to not include any quotes or other text, copy the whole text which is marked in blue below.
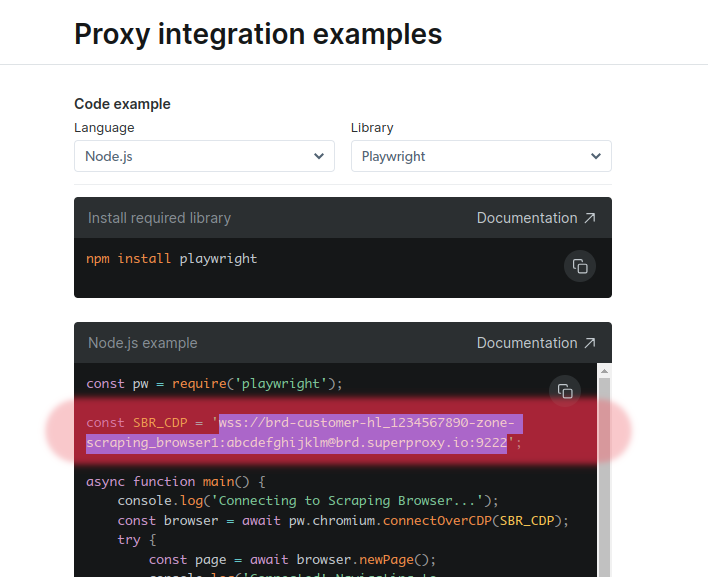
Now for the fun part, jump over to your changedetection.io login and click on Settings > CAPTCHA & Proxies, scroll down to the "Extra Browsers" section, give your browser a name (in this case just BrightData Scraping Browser and paste the wss://... type URL into the Connection URL box
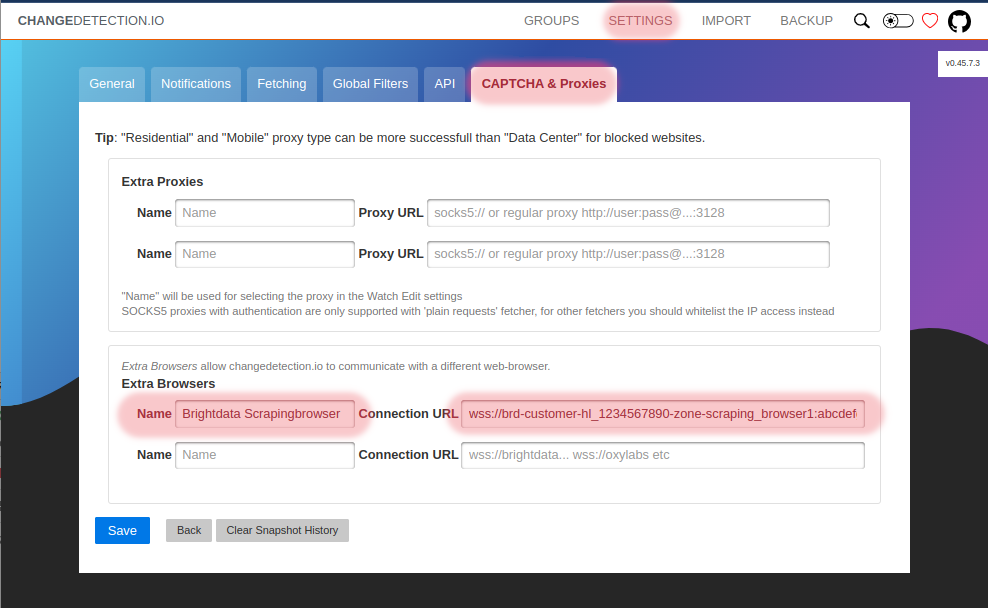
Now to use your new Scraping Browser with any website you are watching for changes, simply click Edit in your overview list and select the new browser

Choose the new browser Bright Data Scraping Browser that we setup in the previous step.
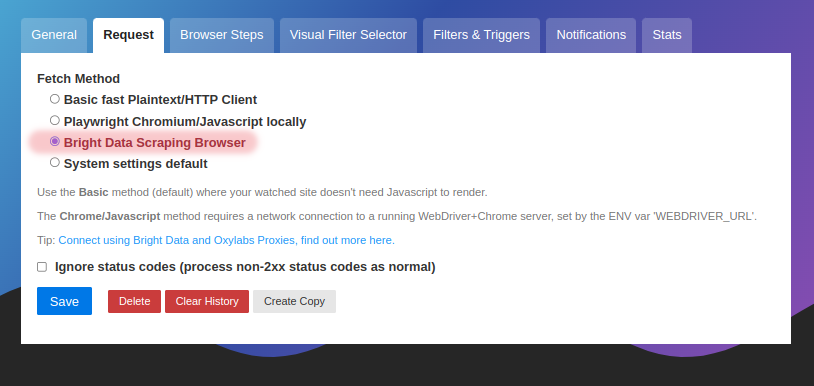
And there you have it - how to setup a scraping browser to get a much better success rate (say goodbye CAPTCHA!) when watching websites for changes.
Some extra tips -
When you setup additional Residential Proxies - Bright Data will present you with a new "wss://.." type connection URL, so you can then setup multiple proxy networks with multiple scraping browsers.
Sign up with Bright Data using https://brightdata.grsm.io/n0r16zf7eivq BrightData will match any first deposit up to $150
Troubleshooting
If you see the error "Overriding accept-language, user-agent headers forbidden" - You may need to enable "Custom headers" - In your Brightdata dashboard - under the Proxy Settings > Configuration > Advanced Settings > Custom headers & cookies this option needs to be activated. (changedetection.io may send its own custom User-Agent and other headers)
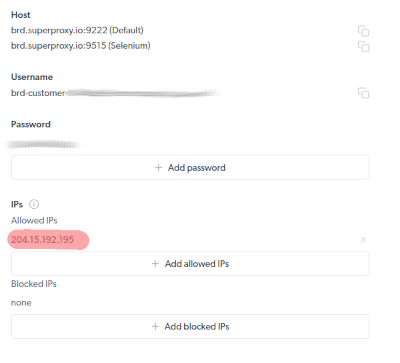
If you receive an error like "WebSocket error: wss://brd-customer..... 403 wrong_auth" then try whitelisting the IP of our server (or your local connection) from inside the BrightData control panel at the "Scraping Browser" settings - as an alternative to username+password (But still keep the username+password in the wss://.. connection URL)
Happy changedetecting!
extra points! You can now use the built-in proxy scanner to see which websites still give the 403 access denied error, check it out here https://changedetection.io/tutorial/find-best-proxy-beat-403-access-denied-our-proxy-scanner